


LLM evaluation: 從提示手工藝到提示工程
探討AI專案中評估的重要性,從提示手工藝到提示工程的轉變。介紹自動化評估系統、feedback機制和大語言模型評估方法,助您優化AI應用。


❏ 引言
來看一段 AI 專案驗收會議上的真實對話:
客戶👸: 這個案子你們只用 prompt engineering (提示工程) 做?有用到其他 ML 方法嗎?
我們🤓: 是的,包括"非結構化的文字處理"、"風險分類"、"修改建議",在這次的 POC 專案中主要都是利用 prompt engineering 做到的。
客戶👸: 如果未來我們有更多種檔案格式需要支援或是需要增加新分類,prompt 是不是又要修改?prompt 越寫越長,token 越用越多,不會很貴嗎?
...
客戶👸: 雖然你們的結果有做到高於驗收標準,但是我們的 user 使用起來體驗還不是不太好,如果要請你們進一步優化,你們會怎麼做?也是只改改 prompt 嗎?
我們🤓: 可能會嘗試搭配其他 ML 方法或是 RAG 架構,但在 POC 階段我們會以 prompt engineering 為主沒錯。
客戶👸: 你們改 prompt,錯的可能會變成對的,但是會不會原本對的反而變成錯的?你們只是在調調 prompt 而已嗎?
我們🤓: ... ... (往下捲到結語)雖然這段對話隱約有種客戶在凹的感覺,但其實也揭露了 AI 專案常見的挑戰和盲點:
如何確立一個 AI 應用帶來的商業價值
如何將這份價值映射至可量化的指標
如何系統化的持續優化這個指標
如何與客戶就以上三點達成共識
這期我們來聊聊 Evaluation (評估) 在 AI 應用開發上 (尤其是 GenAI) 的重要性:到底你是在做 Prompt engineering 還是 Prompt handicraft (手工藝)。
❏ 評估在工程上的意涵
❏ 提示手工藝 (Prompt handicraft)
❏ 提示工程 (Prompt engineering)
✔ 佈署前: 建立自動化的價值評估系統
✔ 佈署後: 建立 feedback 機制持續優化評估系統
❏ 大語言模型評估方法
✔ 自動基準測試
✔ 人工評估
✔ 模型自評估 (LLM-as-a-Judge)
👋 嘿,我是 Browny。
非正式寫作 著墨琢磨 技術趨勢、溝通領導、概念理解 與 生活實踐。
每週一四派送,免費訂閱起來👇
🔍 工人智慧猜你也喜歡
❏ 評估在工程上的意涵
生成式 AI 能舉一反三令人為之驚艷
這份創意(不確定性)在工程實踐中帶來挑戰與機會
大語言模型 (LLM) 本質上是對文字的機率性接龍,透過大量的資料訓練,讓這個預測符合我們的預期。比如,當我向模型輸入 “人工智能正在改變...”,模型就會開始預測接下來應該接什麼詞句比較適合,像是:”我們的生活 (30%)”、”未來 (15%)”、”工作方式 (10%)”,等等…。
可以看到,模型的預測是機率性而非決定性的 (1st: 人工智能正在改變我們的生活、2nd: 人工智能正在改變我們的世界、3rd: …)。這種非決定性,對工程提出了巨大的挑戰 (如果程式每次跑的結果都不一樣的話,可能是場災難)。
傳統軟體工程 (GenAI以前的軟體工程) 依賴確定性的測試 (Testing):預設輸入 → 預期輸出。然而,LLM 的出現要求我們轉向更高層次的評估 (Evaluation)。包含輸出的品質、相關性、實用性等等…,不僅僅是字串/數字上的 match 而已。
面對這個本質,我們需要將這份不確定性,提前帶入解決問題的思考當中。我們需要更直接地關注業務目標:這個問題是否真需要確定性的輸出 (分類任務? 評分任務?),模型的輸出如何提升決策效率帶來具體的業務價值?
例如,在客服場景中,重點可能是模型理解問題的能力,以及提供有用信息的質量,而非一個制式呆板的樣本答案。
.
❏ 提示手工藝 (Prompt handicraft)

Insanity is doing the same thing over and over again and expecting different results
什麼叫瘋子,就是重複做同樣的事情還期待會出現不同的結果
But,對 LLM 輸入同樣的東西,的確會有不同結果,這並不瘋狂。不滿意 AI 的答案時,最簡單的策略就是重問一次 XD。
使用大語言模型就像是和一位博學多聞的頑皮助手打交道,而 Prompt Engineering (提示工程) 就是和這位助手有效溝通的系統化步驟:怎麼問一個好的問題、怎麼引導這位助手完成你交辦的任務。
提示工程常見的作法像是提供更多的上下文,例:你想請 AI 幫你規劃台北兩天一夜的假日行程,比起直接問 “台北兩天一夜的假日行程” ,你可以多提供角色設定,像是:”你是一位專業的導遊,請幫我規劃台北兩天一夜的假日行程”。或是添加條件限制,像是:”你是一位專業的導遊,請幫我規劃...,預算要在 5000 元以內”。
更多的上下文和條件限制 (比較豐富的提示),讓模型「有機會」表達的更加精確。注意「有機會」這個 term,也就是說提式的改變有可能讓回答變得更好也有可能變得更差。
然而,如果我們僅僅是透過手動方式不斷嘗試不同的提示,這種做法更像是在進行手工藝而非工程。想像一下這個場景:你修改了一個提示,運行對話,發現效果不佳;於是你再稍微調整一下,再次運行對話,這次似乎有所改善;最後你決定採用第二組提示。
客戶👸: 你們改 prompt,錯的可能會變成對的,但是會不會原本對的反而變成錯的?你們只是在調調 prompt 而已嗎?還有印象上面客戶說的一句話嗎? “反覆試錯” 會讓人覺得只是在調調 prompt 而已 ~
.
❏ 提示工程 (Prompt engineering)
前面我們理解到,若只是憑著直覺和記憶,反覆嘗試不同的提示效果,很容易就落入瞎子摸象的陷阱當中。也許找到了局部最佳,但是面對更多樣本時,全域表現反而是下降的。
那麼,我們怎麼利用工程思維來解決這個問題呢?回到一開始的對話引出的三個挑戰:
如何確立一個 AI 應用帶來的商業價值
如何將這份價值映射至可量化的指標
如何系統化的持續優化這個指標
.
✔ 佈署前: 建立自動化的價值評估系統
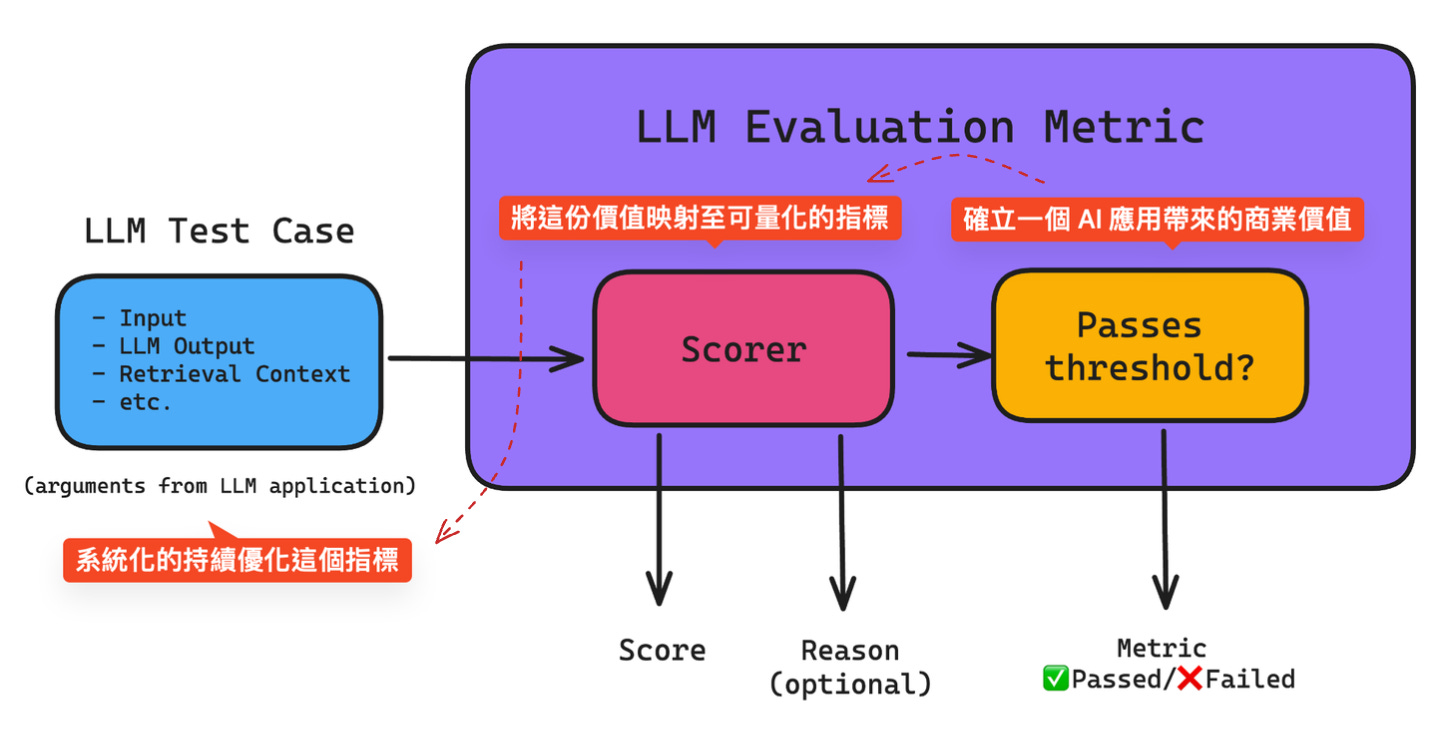
首先,確立一個 AI 應用帶來的商業價值。舉例來說,今天要作一個 “AI 詐騙偵測”,那麼你要優化的這個 threshold (上圖右 Passes threshold) 可能就是 Recall (所有詐騙次數中,系統抓到幾次);換個例子,如果要做的是一個 “AI 會議記錄摘要”,雖然 threshold 就會比較主觀抽象一些 (像是簡潔度,是否有抓到重點,等等…),仍可以找到一些量化評估方法 [2]。
將這份價值映射至可量化的指標:商業價值的 threshold 可以由一或多個客觀的技術指標綜合而得 (上圖中 Scorer),這些技術指標可以透過系統化的持續優化 (上圖左 LLM Test Case),在每一次的 prompt 調整後,客觀的告訴我們哪些 case 表現提升了、那些 case 表現下降了。
.
✔ 佈署後: 建立 feedback 機制持續優化評估系統
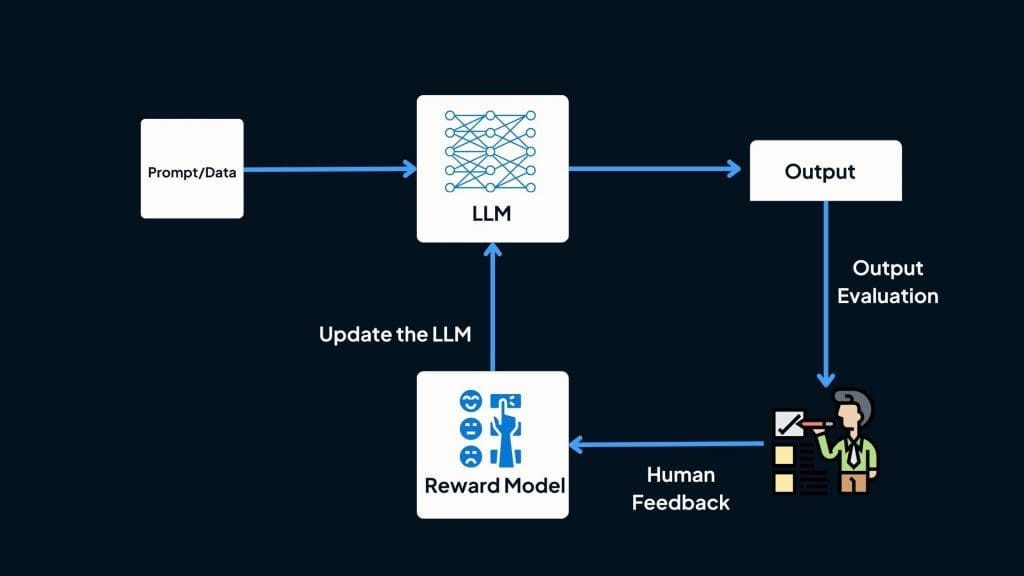
另一個重要的關鍵就是 LLM Test Case 的完備程度。由於模型的不確定性,由於使用者會如何使用的不確定性,很多對話模式在佈署前是無法預料的,所以佈署之後的 feedback loop 就會是系統能否持續適應、持續優化的關鍵。
如上圖,每次的輸出透過直接/間接的 UX 方式,將我們對於表現的喜好傳遞回來,利用這些實際運行的反饋資料,擴增 LLM Test Case,讓提示越來越貼近業務場景,讓提示更加完備。
.
❏ 大語言模型評估方法
評估大語言模型 (LLMs) 是很大的議題,也是持續在發展中的前沿技術 (有空我們再來深入聊聊),這邊大致介紹三種主要的方法:自動化基準測試、人工評估和基於模型的評估:
✔ 自動基準測試
自動化基準測試使用預定義的數據集和指標來評估 LLM 在特定任務上的性能。
數據集:基準測試包含樣本集合或輸入提示,以及預期輸出 (也稱為「真實答案」)。這些樣本旨在模擬您想要評估模型的真實世界任務。
指標:指標用於計算模型性能的分數。選擇的具體指標取決於任務,但常見的指標包括準確性、事實正確性、幻覺、相關性、困惑度和責任性 [4]。
挑戰:自動化基準測試的一個重大挑戰是污染,即基準數據集最終出現在 LLM 的訓練數據中。那就球員間裁判啦 XD。
.
✔ 人工評估
有些品質,如寫作風格、創意和實用性,往往需要人類的判斷。因此,研究者們開發了多種人工評估方法,包括:
氛圍檢查:評估模型輸出的整體感覺
競技場式比較:如 LMSYS Chatbot Arena,讓不同模型直接對決 (群眾外包)
系統性註釋:專家對模型輸出進行詳細分析
然而,人工評估也不是完美無缺的。它可能受到確認偏見、主觀性、文化差異的影響,有時甚至會過於注重語氣而忽視事實準確性。最重要的是,這個太花時間了,基本上就是手工藝。
.
✔ 模型自評估 (LLM-as-a-Judge) [5]
這是一種新興的評估方法,即讓一個大語言模型來評判另一個模型的表現。
優點:
速度:基於 LLM 的評估比人工評估快得多,LLM 能夠更迅速地處理和評估文本。
成本效益:特別是在大規模評估中,使用 LLM 進行評估比聘用和管理人工評估者更具成本效益。
挑戰:
偏見:
位置偏見:傾向於偏好特定位置出現的回應 (請模型比較兩個 response A, B 哪個比較好的時候,LLM judge 可能都會選擇 A 因為他排在比較前面 or 後面)。
冗長偏見:傾向於偏好較長的回應,即使這些回應並不一定更具資訊量 (模型喜歡講廢話的人 so sad ~)。
自我提升偏見:對自己生成的輸出表現出偏好 (偏好自己的同類)。
不一致性:LLM 的判斷可能不夠一致,這使得難以依賴它們進行客觀和可靠的評估 (裁判本身也具備不確定性,一下判好球一下判壞球 ???)。
缺乏透明度:理解 LLM 評分背後的推理邏輯可能具有挑戰性。這種不透明性使得難以解釋評估結果,並識別錯誤或偏見的根本原因。
在實際應用中,模型自評估通常會與其他評估方法結合使用:
混合方法:將自動基準測試與模型自評估相結合提供更均衡的視角。舉例來說,自動化指標可能負責評估事實準確性,而模型自評估則負責評估寫作品質或內容連貫性。
集成方法:使用多個大語言模型作為評判,每個模型都有其獨特的優勢和劣勢,這種方法可能會平衡個別模型的偏見,從而提高整體評估的可靠性。
.
❏ 結語
An unexamined life is not worth living
未經審視的生活是不值得過的。未經自動化評估的提示工程不配稱作提示工程。
客戶👸: 你們改 prompt,錯的可能會變成對的,但是會不會原本對的反而變成錯的?你們只是在調調 prompt 而已嗎?讓我們自信的回答:
我們🤓: 很高興你這麼問。
我們針對 prompt 的迭代和優化是遵循完善的自動化評估方法,是 prompt engineering。
當中涉及了 測試樣本的準備、技術指標的挑選、商業價值與專案目標的對齊。
這每一步都有大量的 know-how 和付出的努力,並不是只是調調 prompt 這樣的手工藝喔。你也在開發 LLM application 嗎? 你用什麼樣的指標來評估你的 AI 應用呢? 歡迎與我分享你的經驗,也歡迎與我討論你遇到的問題,我們下期見 :)
~
🔖 參考資料
[1] LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide - https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
[2] LLM Evaluation For Text Summarization - https://neptune.ai/blog/llm-evaluation-text-summarization
[3] Reinforcement Learning with Human Feedback in LLMs: A Comprehensive Guide - https://thisisrishi.medium.com/reinforcement-learning-with-human-feedback-in-llms-a-comprehensive-guide-771b381e94e7
[4] How does LLM benchmarking work? An introduction to evaluating models - https://symflower.com/en/company/blog/2024/llm-evaluation-101/
[5] Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge) - https://eugeneyan.com/writing/llm-evaluators/
[6] Let's talk about LLM evaluation - https://huggingface.co/blog/clefourrier/llm-evaluation
我自己最近因爲工作和興趣關係,在學習 RAG 相關技術。你這篇文章很有意思,謝謝分享;尤其是位置偏見和集成 LLM 的做法,我之前沒聽說過。
有一個問題:我沒有太看懂「自動基準測試」和「模型自評估」的區別?難道自動基準測試,可以避免使用 LLM 嗎?主要是好奇,如果不用 LLM,還可以怎樣比較系統的回覆和預期輸出...