


從關鍵字到語義: Exa 如何顛覆傳統搜尋引擎
探索 Exa AI 的超級知識與創新搜尋技術,重塑資訊檢索的未來


「智能」與「知識」是不同的概念。
「智能」是對輸入資訊的推理,而「知識」則是從資料庫中擷取資訊的過程 [1]
👋 嘿,我是 Browny,颱風天大家注意安全唷 🌀。
Informal Writing 書寫琢磨 技術趨勢、溝通領導、概念理解與生活實踐。
每週一四派送,訂閱起來👇。也在 threads 上面分享比較 即時的 insight,歡迎關注 👀
📌 引言
嘿,親愛的讀者,這週過的好嗎? 進入炎炎夏日也一段時間了,AI 市場上各類應用也打的火熱。模型推陳出新的頻率之高,一下子 Claude 3.5 Sonnet,一下子又 gpt-4o mini。舊的還沒用熟,新的又出來,市場的信號很多,雜訊也很多。
讓 非正式寫作 來幫你篩選這些訊息:我會定期分享那些吸引到我注意的有趣應用,以及我嘗試在日常的工作流當中,引入這些新工具的經驗,它們帶來哪些好處與驚喜 (缺點也會講講)。對生產力工具有熱誠的朋友,別忘了右上角訂閱起來 👆
在前面幾期的電子報中,我多次提到 AI 為搜尋領域帶來的變革與創新,其中 Perplexity 這個服務已經成為我 顧問研究 與 寫作工作 流程不可或缺的一環:
Organizing the world's knowledge with embeddings search
用 語義(嵌入) 搜尋組織全世界的知識 - @ExaAILabs
今天要和大家分享的是 Exa AI (exa.ai) 這間公司/這個服務,概念上和 Perplexity 有些類似,但鎖定的 scope 更為底層:想要從本質上 (資訊檢索的方式) 推翻傳統關鍵字搜尋所遭遇的困境。
.
📌 誕生背景和使命
我們認為,這種現象在 Google 搜尋品質下降的情況中表現得最為明顯。
有一整個產業 — 搜尋引擎最佳化 (SEO) — 專門研究如何在 Google 搜尋結果中獲得更高排名,目的就是要「將你的注意力轉化為商業利益」。[2]
如同 Exa 的官方部落格所說 [2],Google Search 已經出現超過 10 多年,但搜尋的技術進展並不大,主要還是依賴「關鍵字」比對。所以,為了在搜尋結果排行中爭奪使用者的注意力,甚至出現了一整個 SEO 產業:研究如何幫內容下關鍵字、以及一系列可以提高內容在搜尋引擎當中名列前茅的技巧。
所以,那些排名前三的結果,真的最切合你想要的答案嗎?很多時候未必如此,那些結果是業者花錢做 SEO 買到的注意力版位。更嚴重的,搜尋結果還會直接穿插一些直接的廣告內容。
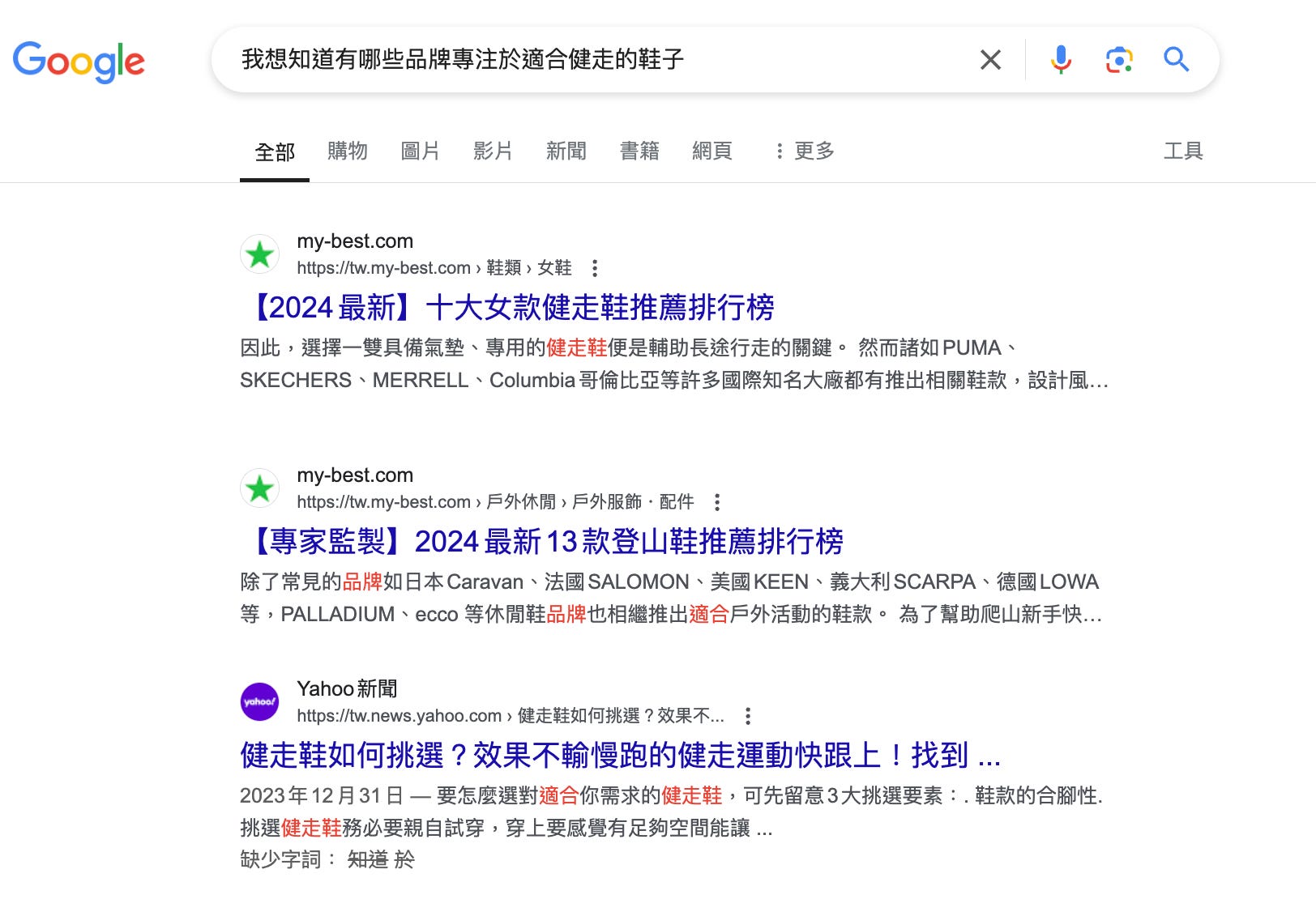
如上圖,我輸入的查詢是:「我想知道有哪些品牌專注於適合健走的鞋子」,但是 Google 前面幾筆查詢結果是一些評測文還有如何挑選鞋款的文章,濃濃的商業氣息。這也不能怪它,畢竟搜尋引擎的商業模式,本來就是靠競爭注意力來轉起這個神奇飛輪。那麼,同樣的搜尋,在 Exa 裡面會得到什麼結果呢?
.
📌 核心技術
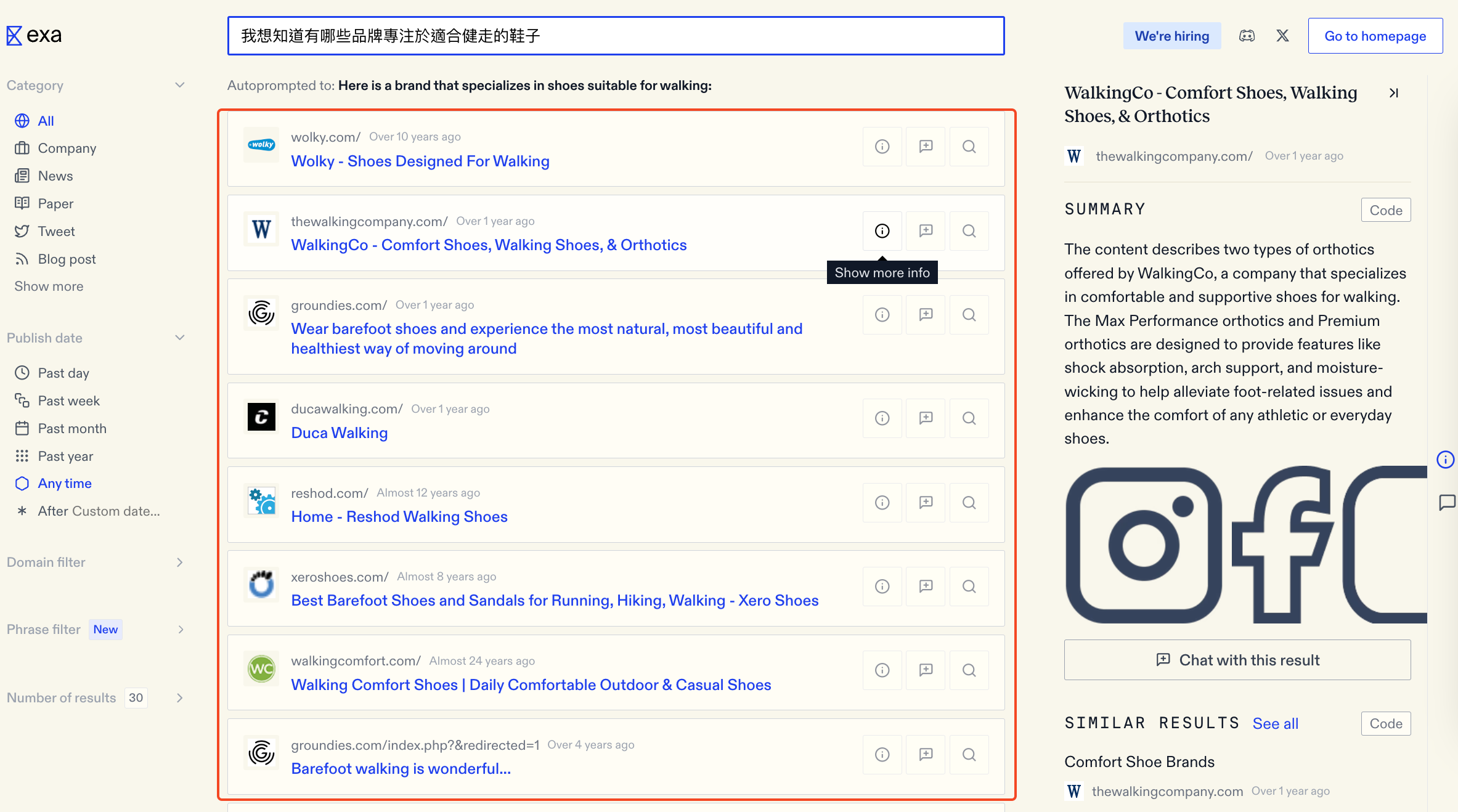
如上圖,可以看到 Exa 的結果直接列出品牌的官方網站,正面答復了我的問題,更切合我的需求,不會推給我什麼 2024 鞋子評測或是如何挑選鞋款這種跟我的問題沒有直接關聯的回答。
介面上,左邊可以針對 Tweet 和 Blog post 做篩選,可以針對一些比較新的議題,做到即時性。在每一個搜尋結果上,也整合進 AI 的功能:對結果做摘要、列出相似結果以及直接跟該比結果內容進行聊天。
從公司的願景:”Organizing the world's knowledge with embeddings search” 可以大概看出核心的技術之一是嵌入搜索,這沒什麼特別,因為 RAG 就是利用這種方式讓 LLM 擴充關於事實的知識,但是要做到整個 internet 的規模,還是相當驚人的。
此外,其官網部落格也透漏出,它利用 LLM 的方式去訓練一種他們認為好的搜索結果應該具備的特質:

以上述的例子來說,Exa 做的事情其實是在訓練的時候蒐集類似下面的資料:
我最近開始健走,我發現 OOO 牌子的鞋子很適合: [link to OOO]
昨天去爬 ABC 山,整趟走下來腳都不會酸耶,XXX 也太好走了吧: [link to XXX]
然後,當我今天把「我想知道有哪些品牌專注於適合健走的鞋子」的查詢輸入之後,會先轉為 Embeddings 去比對相似度高的語境 (也就是上面那兩句會被 match 到),然後模型就會生成出適合的官網連結 (OOO, XXX 的 link)。
真是太驚人了對吧,這就像是去訓練一個非常擅長「推薦」的生成模型。讓我聯想到最近紅起來的 GraphRAG [3]:LLM 本身已經具備了強大的語言理解能力,RAG 進一步提供他事實,降低它的幻覺。
若有一種表達方式 (Graph) 可以讓 LLM 更好的學習到「關聯」,那麼他的能力有可能大幅提升。就像 連結 (URL) 與 分享/推薦行為 這樣的關聯,Exa 用 LLM 的訓練方式讓模型學習起來,在搜尋的領域,就有可能是一個重大的典範轉移!
.
📌 傳統搜尋引擎的比較

除了上述利用「語義」而非「關鍵字」的方式進行搜尋以外。Exa 另一個和傳統搜尋引擎不同的地方是:它是面向 LLM 應用開發者的。意思是,它希望打造一個能夠讓各類 LLM 應用開發商在取用資料的時候,可以有更高的資料品質,而不是只能仰賴現今的搜尋引擎 (被 SEO 搞砸的那些)。
所以,Exa 主要的商業模式,應該還是在怎麼與這些 LLM 應用開發商,做更好的底層資料 Retrieval 整合。也許在不同產業,需要有不同的訓練方式也說不定。Exa search 應該只是一個讓大家理解他們在做什麼的一個通用性 showcase 吧。
.
📌 超級知識 (Superknowledge)
超級智能是一種能夠處理極為複雜「推理」請求的系統,
而超級知識則是一種能夠處理極為複雜「檢索」請求的系統。
有趣的是,目前似乎只有我們在進行這項研究。儘管有數十個實驗室正在研究超級智能,但據我所知,全世界只有一個組織在致力於超級知識的研究 — 那就是 Exa。
這種情況的部分原因在於,建立超級知識系統需要一個具有正確激勵機制的組織。那些依賴廣告收入的組織不太可能投入此項研究。相比之下,Exa 採用了基於使用量的收入模式。我們有強烈的動機為用戶提供完全的控制權,使他們能夠檢索所需的任何知識。事實證明,用戶願意為獲得超級知識付出相當高的代價。[1]
我覺得最後一段挺有意思的,應該是在說 Google 的廣告收入這麼賺,在還沒看到明顯利益的時候,是不會跳下來作這一塊的吧 XD!
而 Exa 的策略則是面向 LLM 應用開發商,提供他們 Superknowledge,讓應用開發商可以更專注在自身商業模式和用戶體驗,讓知識搜尋/檢索的部分,外包給 Exa 的 API。
後續這個領域會怎麼發展,我覺得還說不太定 (這個東西如果 Google 要跳下來做,技術上我覺得應該也不會有什麼阻礙)。但是 Exa search 的表現的確令人眼睛為之一亮,不禁也令人思考,一些已經理所當然的技術範式,是不是也有機會搭著這波 LLM 風潮,再次偉大?
.
📌 結語
隨著人工智能技術的飛速發展,我們正站在搜尋革命的前沿。Exa AI 的出現不僅挑戰了傳統搜尋引擎的範式,更為我們展示了一個充滿可能性的未來。從關鍵字匹配到語義理解,從商業導向到用戶需求為中心,這種轉變標誌著我們正在邁向一個更智能、更精準的信息檢索時代。
Exa 的 "超級知識" 概念為 LLM 應用開發者提供了強大的工具,有潛力徹底改變我們獲取和處理信息的方式。然而,這場革命才剛剛開始。未來,我們可能會看到更多創新者加入這個領域,推動搜尋技術向更高層次發展。
現在我越來越多的搜尋是花在 Perplexity 和 Exa 上面,真的找不到,我才會打開 Google。十年以後,要上網找東西的時候,大家還會說:「去 Google 一下嗎?」
~
🔖 參考資料
[1] We need superknowledge before superintelligence - https://exa.ai/blog/superknowledge
[2] Building Search for the Post-ChatGPT World - https://exa.ai/blog/building-search-for-the-post-chatgpt-world
[3] The GraphRAG Manifesto: Adding Knowledge to GenAI - https://neo4j.com/blog/graphrag-manifesto/